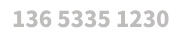
Т»ЎўДЪҙжКэҫЭҝвіцПЦөДұіҫ°
ЎЎЎЎФЪҙ«НіөДКэҫЭҝвұнЦРЈ¬УЙУЪҙЕЕМөДОпАнҪб№№ПЮЦЖЈ¬OLTPАаІЩЧчТэЖрөДЛж»ъІйХТ»бёшIOПөНіҙшАҙёЯ°әөДҝӘПъЈ¬ТтҙЛҙ«НіөДұнәНЛчТэөДҪб№№ЙијЖОӘК№УГB-Tree¶шҫЎБҝјхЙЩЛж»ъІйХТЈ¬ө«УЙУЪ»ъРөҙЕЕМәНКэҫЭҝвЛшөДҙжФЪЈ¬B-TreeҪб№№ФЪҙҰАнҙуІў·ўөДOLTP»·ҫіКұҫНПФөГ·ЗіЈ·ҰБҰЈ¬ЛдИ»УРәЬ¶а°м·ЁАҙҪвҫцХвАаОКМвЈ¬ұИИзЛөАЦ№ЫІў·ўҝШЦЖЎўУҰУГіМРт»әҙжЎў·ЦІјКҪјЬ№№өИЈ¬ө«ІЙУГЙПКц·Ҫ°ё»бөјЦВРЮёДТэУГіМРтЈ¬ХвІ»ҪціЙұҫёЯЗТ·зПХј«ҙуЎЈ¶шЛжЧЕХвР©ДкУІјюөД·ўХ№Ј¬ПЦФЪ·юОсЖчУөУРјё°ЩGДЪҙжІўІ»әұјыЈ¬ҙЛНвУЙУЪУІјюNUMAјЬ№№өДіЙКмЈ¬ТІПыіэБЛ¶аCPU·ГОКДЪҙжөДЖҝҫұОКМвЈ¬ТтҙЛҫЯұёБЛК№УГРВ·ҪКҪАҙҙҰАнёьҙуІў·ўәНКэҫЭБҝөДМхјюЈ¬ХвЦЦРВөД·ҪКҪҫНКЗК№УГДЪҙжјЖЛгјјКхЎЈ
ЎЎЎЎДЪҙжөДС§ГыҪРЧцRandom Access Memory(RAM)Ј¬ТтҙЛИзЖдМШРФТ»СщЈ¬КЗЛж»ъ·ГОКөДЈ¬ТтҙЛ¶ФУЪДЪҙжЈ¬Лж»ъІйХТІ»»бТэИл¶оНвҝӘПъЈ¬К№УГHash-IndexХвСщөДКэҫЭҪб№№ёь·ыәПДЪҙжөДМШРФЈ¬¶ш¶ФУҰІў·ўөДёфАл·ҪКҪТІ¶ФУҰөДұдіЙБЛMVCC(¶а°жұҫІў·ўҝШЦЖ)Ј¬ҙУ¶шПыіэБЛЛшТэИлөДРФДЬЖҝҫұЎЈТтҙЛДЪҙжКэҫЭҝвҝЙТФФЪН¬СщөДУІјюЧКФҙПВЈ¬ҙҰАнёь¶аөДІў·ўәНЗлЗуЈ¬ІўЗТІ»»бұ»ЛшЧиИыЈ¬ФЪSQL Server 2014ЦРЈ¬јҜіЙБЛХвёцЗҝҙуөДДЪҙжКэҫЭТэЗжЈ¬Из№ыҪбәПSSD AS Buffer PoolМШРФЈ¬ЛщІъЙъөДР§№ыҪ«»б·ЗіЈЦөөГЖЪҙэЎЈ
ЎЎЎЎ¶юЎўSQL ServerДЪҙжКэҫЭҝвөДЧйіЙәНұнПЦРОКҪ
ЎЎЎЎФЪSQL Server 2014өДДЪҙжКэҫЭҝвТэЗжУЙБҪІҝ·ЦЧйіЙЈәДЪҙжУЕ»ҜұнәНұҫөШұаТлҙжҙў№эіМЎЈЛдИ»ДЪҙжКэҫЭҝвјҜіЙҪшИл№ШПөКэҫЭҝвТэЗжЈ¬ө«·ГОКДЪҙжКэҫЭҝвөД·Ҫ·Ё¶ФУЪҝН»§¶ЛАҙЛөКЗНёГчөДЈ¬ХвТІТвО¶ЧЕҙУҝН»§¶ЛУҰУГіМРтөДҪЗ¶ИАҙҝҙЈ¬ІўІ»»бЦӘөАДЪҙжКэҫЭҝвТэЗжөДҙжФЪЎЈИзНј1ЛщКҫЎЈ
ЎшНј1.ҝН»§¶ЛAPPІ»»бёРЦӘHekatonТэЗжөДҙжФЪ
ЎЎЎЎКЧПИДЪҙжУЕ»ҜұнНкИ«І»»бФЩҙжФЪЛшөДёЕДо(ЛдИ»Ц®З°өД°жұҫУРҝмХХёфАлХвёцАЦ№ЫІў·ўҝШЦЖөДёЕДоЈ¬ө«ҝмХХёфАлИФИ»РиТӘФЪРЮёДКэҫЭөДКұәтјУЛш)Ј¬ҙЛНвДЪҙжУЕ»ҜұнHash-IndexҪб№№К№өГЛж»ъ¶БРҙөДЛЩ¶Иј«ҙуМбёЯЈ¬ДЪҙжУЕ»Ҝұн»№ҝЙТФЙиЦГОӘК№УГ·ЗіЦҫГ»ҜИХЦҫЈ¬јИКэҫЭјИІ»РҙИХЦҫЈ¬ТІІ»»бCheckPointөҪҙЕЕМЈ¬ҙУ¶шј«ҙуөДҪөөНБЛIOС№БҰ(ККәПУЪETLЦРјдҪб№ыІЩЧчЈ¬»тХЯЖдЛыФКРн¶ӘК§КэҫЭөДіЎҫ°)Ј¬ХвСщТ»АҙТІҝЙТФПыіэРҙИХЦҫТэИлөДРФДЬЖҝҫұЎЈ
ЎЎЎЎПВГжАҙҙҙҪЁТ»ёцДЪҙжУЕ»ҜұнЈә
ЎЎЎЎКЧПИЈ¬ДЪҙжУЕ»ҜұнРиТӘКэҫЭҝвЦРҙжФЪТ»ёцМШКвөДОДјюЧйЈ¬ТФ№©ҙжҙўДЪҙжУЕ»ҜұнөДCheckPointОДјюЈ¬Улҙ«НіөДmdf»тldfОДјюІ»Н¬өДКЗЈ¬ёГОДјюЧйКЗТ»ёцДҝВј¶шІ»КЗТ»ёцОДјюЈ¬ТтОӘCheckPointОДјюЦ»»бҪ«РВФцөДКэҫЭёҪјУФЪөҪРВөДCheckPointОДјюЈ¬¶шІ»»бРЮёДПЦУРөДCheckPointОДјюЈ¬ИзНј2ЛщКҫЎЈ
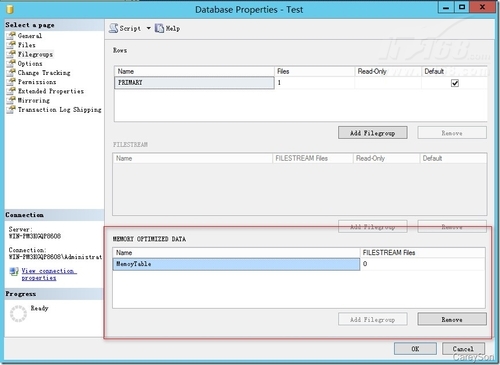
ЎшНј2.ДЪҙжУЕ»ҜұнЛщРиөДМШКвОДјюЧй
ЎЎЎЎПВГжФЩАҙҝҙТ»ПВДЪҙжУЕ»ҜОДјюЧйФЪҙЕЕМПөНіөДҙжҙўРОКҪЈ¬ИзНј3ЛщКҫЎЈ

ЎшНј3.ДЪҙжУЕ»ҜОДјюЧй
ЎЎЎЎҙҙҪЁНкДЪҙжУЕ»ҜОДјюЧйЦ®әуЈ¬ҪУПВАҙФЩҙҙҪЁТ»ёцДЪҙжУЕ»ҜұнЈ¬ИзНј4ЛщКҫЎЈ
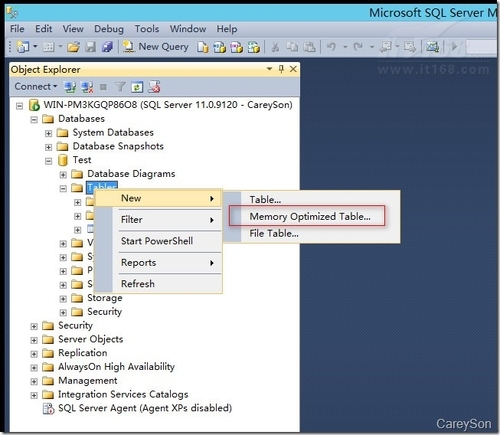
ЎшНј4.ҙҙҪЁДЪҙжУЕ»Ҝұн
ЎЎЎЎДҝЗ°SSMS»№І»Ц§іЦUIҪзГжҙҙҪЁДЪҙжУЕ»ҜұнЈ¬ТтҙЛЦ»ДЬНЁ№эT-SQLАҙҙҙҪЁДЪҙжУЕ»ҜұнЈ¬ИзНј5ЛщКҫЎЈ

ЎшНј5.К№УГҙъВлҙҙҪЁДЪҙжУЕ»Ҝұн
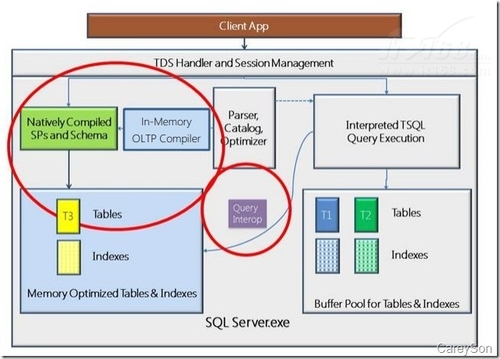
ЎЎЎЎХвАпҙҙҪЁТ»ёцјтөҘөДДЪҙжУЕ»ҜұнЈ¬ХвАпЙПКцЙиЦГHash BucketОӘ1024Ј¬ДҝЗ°SQL Server 2014»№І»Ц§іЦ¶ҜМ¬өДHash BucketЈ¬ТтҙЛұШРлКЦ¶ҜЙиЦГёГЦөЎЈұнЦРЙиЦГБЛMemory_OptimizedОӘONТвО¶ЧЕұнКЗДЪҙжУЕ»ҜұнЈ¬¶шDurabilityЙиЦГОӘSchema_And_DataФтТвО¶ЧЕДЪҙжУЕ»ҜұнЦРКэҫЭТІКЗіЦҫГ»ҜЈ¬ХвТвО¶ЧЕіэ·ЗЖфУГБЛSQL Server 2014өДСУіЩРҙМШРФЈ¬КэҫЭІ»»бУЙУЪТміЈЗйҝцөјЦВ¶ӘК§ЎЈ
ЎЎЎЎөұұнҙҙҪЁәГЦ®әуЈ¬ҫНҝЙТФІйСҜКэҫЭБЛЈ¬ЦөөГЧўТвөДКЗЈ¬ІйСҜДЪҙжУЕ»ҜұнРиТӘsnapshotёфАлөИј¶»тХЯhintЈ¬ХвёцёфАлөИј¶УлҝмХХёфАлКЗІ»Н¬өДЈ¬ИзНј6ЛщКҫЎЈ
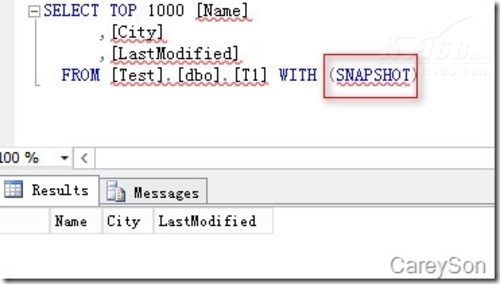
ЎшНј6.ІйСҜДЪҙжУЕ»ҜұнРиТӘјУМбКҫ


